
Seit Ende September 2023 ermöglicht OpenAI Bildrechteinhaber und Urhebern wie Künstler, Autoren, Designer und Fotografen ihre Arbeiten und Werke aus den KI-Trainingsdaten, hier der DALL-E 3 KI-Bildgenerator, zu entfernen. Allerdings ist das Opt-out-Verfahren sehr aufwändig. Zum Schutz des geistigen Eigentums und dem Bewahren vor Mißbrauch, ist die Entfernung aus den DALL-E-Trainingsdaten eine sehr empfehlenswerte Angelegenheit für alle Urheber.
Damit KI-Modelle bestmöglich funktionieren, müssen Trainingsdaten verarbeitet werden. Mittlerweile wetteifern die KI-Anbietern darum, möglichst viele Daten zu sammeln, um überzeugende Ergebnisse zu erzielen.
Woher stammen die Bilddaten, die für die Erzeugung von KI generierten Bildern genutzt werden?
Genaue Informationen darüber, welche Bilder für das Training von KI-Bildgeneratoren verwendet werden, sind wenig bekannt. Es ist allerdings davon auszugehen, dass alle Modelle die im Internet und in den sozialen Medien verfügbaren Bilder zum Training ihrer Modelle nutzen, ohne die Urheber um Erlaubnis zu fragen.
Eines ist auf jeden Fall klar: Es fließen unzählige, von Menschen geschaffene Werke, die im Netz veröffentlicht wurden in die Trainingsdaten von KI-Modellen ein. Neben den Urheberrechtsverletzungen kann das auch existenzbedrohende Folgen für Künstler und Urheber haben.
Die KI-Anbieter stehen deshalb inzwischen unter Druck. Sie müssen Urhebern die Möglichkeit geben, sich entweder aktiv für die Teilnahme an dem KI-Experiment oder für die Löschung ihrer Daten zu entscheiden.
Spätestens jetzt solltest du dir die Frage stellen, wo du deine Werke im Netz öffentlich zugänglich sind und wo du möglicherweise direkten Einfluß darauf hast, sie aus den Trainingsdaten von KI-Modelle zu entfernen.

Wie du Bilder aus dem Trainingsdatensatz von DALL-E entfernen kannst
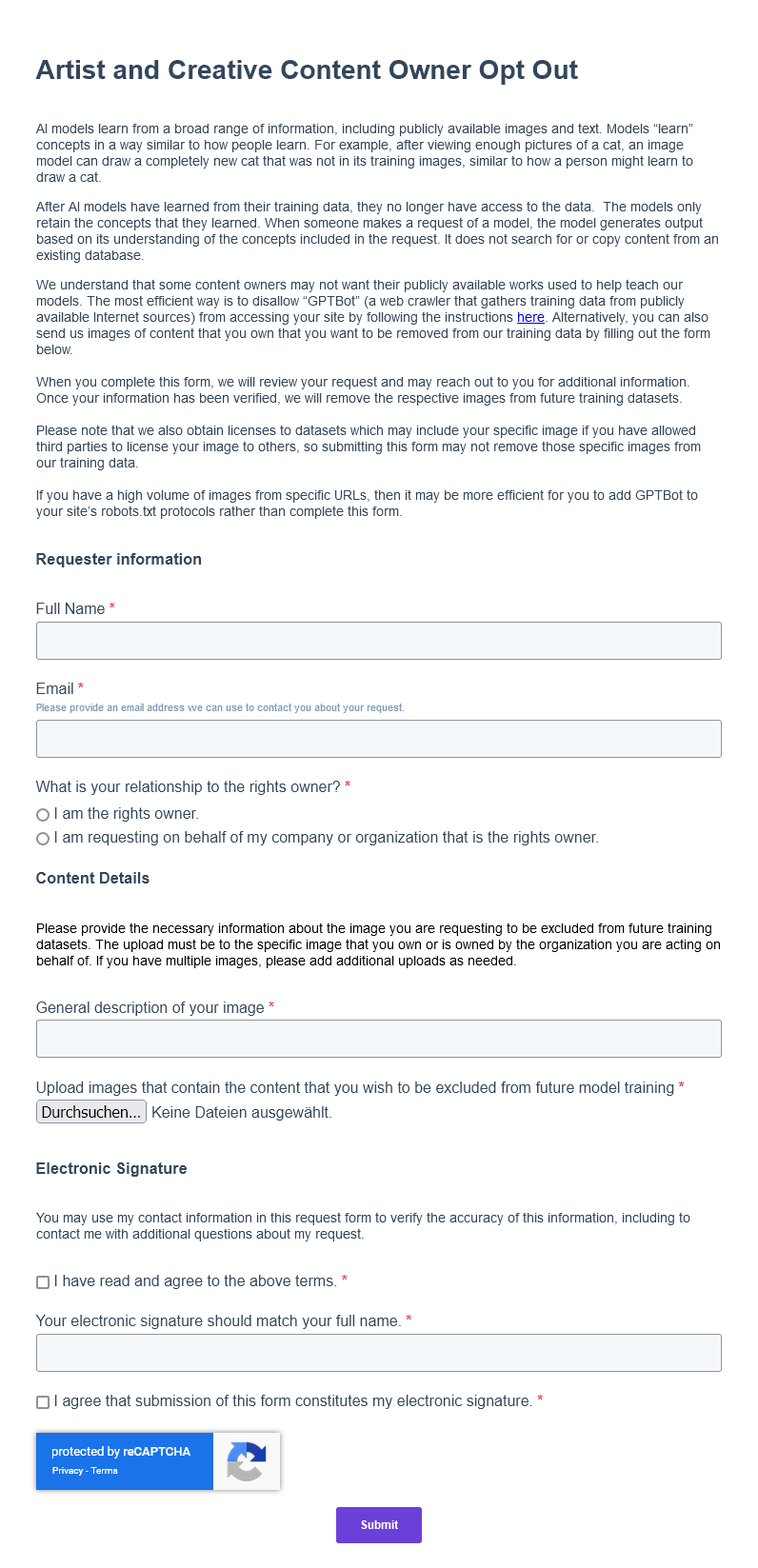
Wenn du als Urheber oder Rechteinhaber deine Werke aus dem Trainingsdatensatz von DALL-E löschen möchtest, musst du OpenAI das Bild zusammen mit einer Beschreibung zusenden, um einen Opt-out-Antrag stellen zu können.
Für die meisten Künstler bedeutet dies, dass sie unter Umständen mehrere hunderte oder tausende Werke einzeln einreichen müssen. Dieser unermessliche Aufwand kann schnell zu einer Lebensaufgabe werden.
Sicherlich hätte OpenAI DALL-E so konzipieren können, dass Eigentümer oder Urheber die Möglichkeit gehabt hätten, in einem einzigen Arbeitsgang die Entfernung aller Arbeiten aus den Trainingsdaten zu beantragen. OpenAI entschied sich jedoch dagegen. Warum? Weil OpenAI möglichst viele Daten benötigt, um gute Ergebnisse zu liefern.
Um die Entfernung deiner urheberrechtlich geschützten Fotos und Werke aus den DALL-E-Trainingsdaten zu beantragen, gehe wie folgt vor:
- Rufe die offizielle Seite von OpenAI / DALL-E unter https://openai.com/dall-e-3 auf.
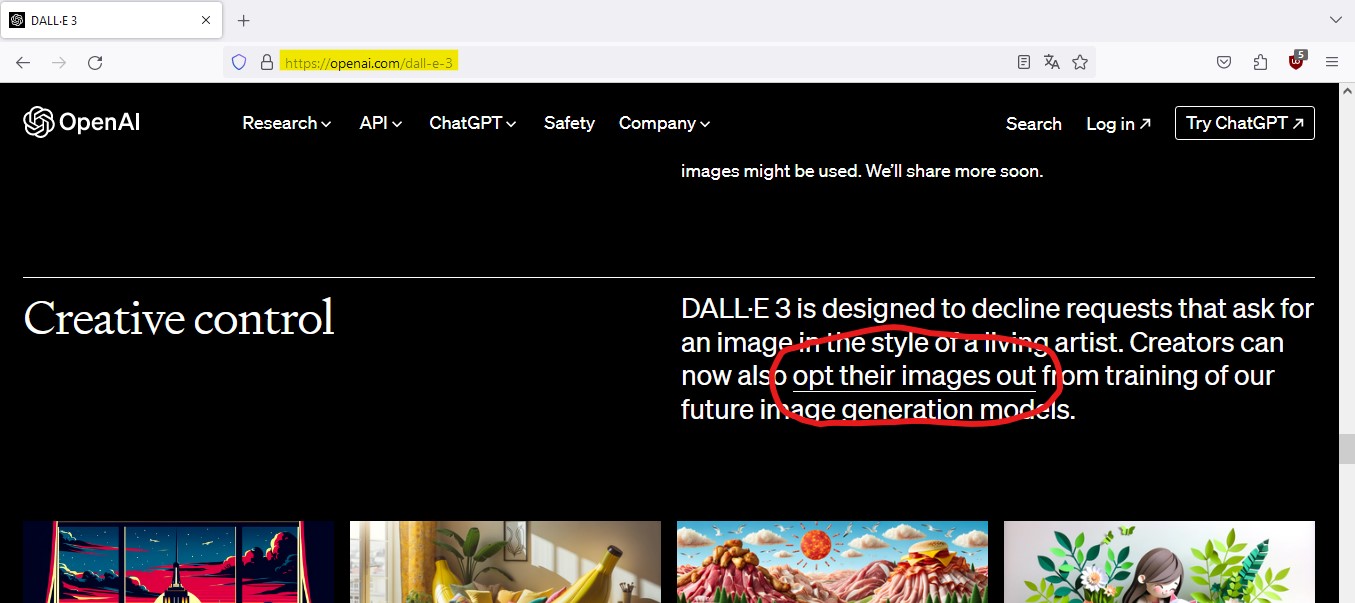
- Scrolle auf der Seite zu der Überschrift „Creative Control“.
- Öffne das Opt-Out-Formular, indem du rechts im Text auf den Link „opt their images out“ klickst, siehe Abb. 2.
- Wenn du dir den Umweg über die Website von OpenAI sparen möchtest, kannst du das Formular natürlich auch direkt unter: https://share.hsforms.com/1_OuT5tfFSpic89PqN6r1CQ4sk30 aufrufen und öffnen.
Formular für das Opt-out des Bildrechteinhabers aus den OpenAI-Trainingsdaten
Selbst wenn OpenAI dem Wunsch eines Künstlers oder Eigentümers nachkommt, sich abzumelden, gilt dies allerdings nur für das „zukünftige“ Training von DALL-E.
Bereits in die Trainingsdaten eingeflossene Werke können nicht mehr aus den Trainingsdaten entfernt oder gelöscht werden!
Zusätzlich führt OpenAI in den Erläuterungen zum Opt-out-Formular folgendes an:
„Bitte beachten Sie, dass wir auch Lizenzen für Datensätze erhalten, die Ihr spezifisches Bild enthalten können, wenn Sie Dritten erlaubt haben, Ihr Bild an andere zu lizenzieren. Durch das Absenden dieses Formulars werden diese spezifischen Bilder daher möglicherweise nicht aus unseren Trainingsdaten entfernt.“
Dritte können beispielsweise Bilddatenbanken, soziale Medien (Facebook, Instagram, Threads usw.), Plattformen wie Behance und Dribble oder auch Cloud-Dienste wie Dropbox sein.
Vertrauen ist gut, Kontrolle ist besser…
Um zu erfahren, ob du möglicherweise beim Hochladen deiner Bilder in die sozialen Medien, in die Cloud oder auf Plattformen Nutzungsrechte deiner Werke an die jeweiligen Anbieter übertragen hast, solltest du deren Nutzungsbedingungen und AGB genau studieren und unter die Lupe nehmen.
Hast du bei Anbietern deine Werke hochgeladenen, die das „Abreifen“ von Daten durch KI-Bots erlauben, hast du Pech gehabt. Du kannst sie nicht mehr aus den Trainingsdaten der verwendeten KI-Modelle löschen.
Dummerweise besteht auch keine Möglichkeit, deine bereits veröffentlichten Werke auf Plattformen wie z. B. Facebook, TikTok oder Instagram aus den Trainingsdaten der jeweils verwendeten KI’s auszuschliessen oder zu löschen. Du solltest dir deshalb Gedanken darüber machen, bei welchen Dritt-Anbietern oder auf welchen Plattformen du deine Werke in Zukunft veröffentlichst und zur Schau stellst.
Ein kleiner Lichtblick: Auf deiner eigenen Website kannst du den GPTBot von OpenAI/DALL-E aussperren
Am effizientesten ist es, dem GPTBot (Webcrawler) von OpenAI den Zugriff auf deine Website zu verweigern. Dazu muss der GPTBot zu der Robots.txt-Datei deiner Website hinzugefügt werden.
Robots.txt:
User-agent: GPTBot
Disallow: /Wenn du den GPTBot nur aus bestimmten Verzeichnissen fernhalten möchtest, sollte deine Robots.txt-Datei folgendermaßen aussehen:
User-agent: GPTBot
Allow: /ordner1/
Disallow: /ordner2/Wenn du wissen willst, ob der GPTBot deine Website bereits besucht und „ausgelesen“ hat, kann du das anhand der Access-Log-Files auf deinem Webserver überprüfen.
GPTBot kann anhand des folgenden Benutzeragenten und der folgenden Zeichenfolge identifiziert werden:
User agent token: GPTBot
Full user-agent string: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.0; +https://openai.com/gptbot)Hält sich der GPTBot an die Vorgaben, die in der Robots.txt-Datei gemacht werden?
OpenAI gab im Herbst letzten Jahres bekannt, dass es sich an die altehrwürdige Praxis von Websites halten wird, Dateien und Verzeichnisse zu scannen und zu verwerten, die lt. der robots.txt -Datei nicht von GPTBot besucht werden dürfen. Ausgeschlossene Dateien und Verzeichnisse sollen lt. OpenAI nicht in die Trainingsdaten von ChatGPT einfliessen.
Im 2. Teil dieser Serie werde ich dir weitere Möglichkeiten und Optionen vorstellen, um die lästigen KI-Bots von deinen Werken fernzuhalten.